
02. Transactionnelles Et Analytiques
Les bases de données transactionnelles gèrent les opérations quotidiennes en temps réel comme les transactions bancaires tandis que les bases analytiques sont optimisées pour l'analyse de grandes quantités de données historiques afin d'en extraire des tendances. Regardons cela plus en détails dans les paragraphes suivants.
Bases de données transactionnelles
Ces bases de données sont au cœur des systèmes de gestion des transactions. Elles sont conçues pour gérer efficacement un grand volume de transactions courtes, individuelles et souvent uniques. Prenons par exemple un achat sur Amazon : lorsqu'un utilisateur finalise son achat, cela déclenche l'enregistrement d'une nouvelle entrée dans la base de données. Cette entrée comprend des informations essentielles telles que le numéro de commande, l'identité de l'acheteur, le montant de la transaction, la date et le statut de la commande. C'est cette capacité à traiter et stocker chaque transaction individuelle qui leur vaut leur nom de base de données transactionnelles.
L'objectif principal de ces bases de données est d'assurer la rapidité, la fiabilité et l'intégrité des données dans des environnements où les opérations d'écriture sont fréquentes.
Elles sont optimisées pour des opérations telles que l'insertion, la mise à jour ou la suppression de données, garantissant ainsi une interaction fluide et efficace pour les utilisateurs finaux.
Bases de données analytiques
En revanche, les bases de données analytiques sont utilisées pour l'analyse de grandes quantités de données. Elles permettent aux data analysts d'extraire des informations pertinentes et de les transformer en indicateurs de performance qui orienteront la stratégie de l'organisation. Imaginons qu'un data analyst cherche à identifier les produits les plus appréciés afin de leur attribuer un badge distinctif - tel que Choix Amazon ou Numéro 1 des Ventes .
Les badges associés aux articles sur Amazon.
Ces bases de données sont optimisées pour la lecture et l'analyse des données, facilitant des requêtes complexes et l'agrégation d'informations sans compromettre la performance des systèmes transactionnels. L'utilisation d'une base de données analytique permet de réaliser des analyses approfondies sans risquer d'altérer les données critiques ou de perturber les opérations quotidiennes.
Transactionnelles vs Analytiques
Les bases de données transactionnelles et analytiques servent deux objectifs différents mais complémentaires dans le paysage de la gestion des données. Les premières facilitent les transactions quotidiennes et les opérations en temps réel, tandis que les secondes permettent une analyse stratégique et détaillée des données accumulées. Cette distinction est essentielle pour les organisations cherchant à optimiser à la fois leur efficacité opérationnelle et leur capacité d'analyse décisionnelle.
Cependant, pour transférer les données de la base de données transactionnelle à la base de données analytique, les entreprises ont besoin de processus spécifiques. Ces processus sont souvent réalisés à l'aide d'outils d'ETL (Extract, Transform, Load) tels que Talend, SSIS ou Airflow.
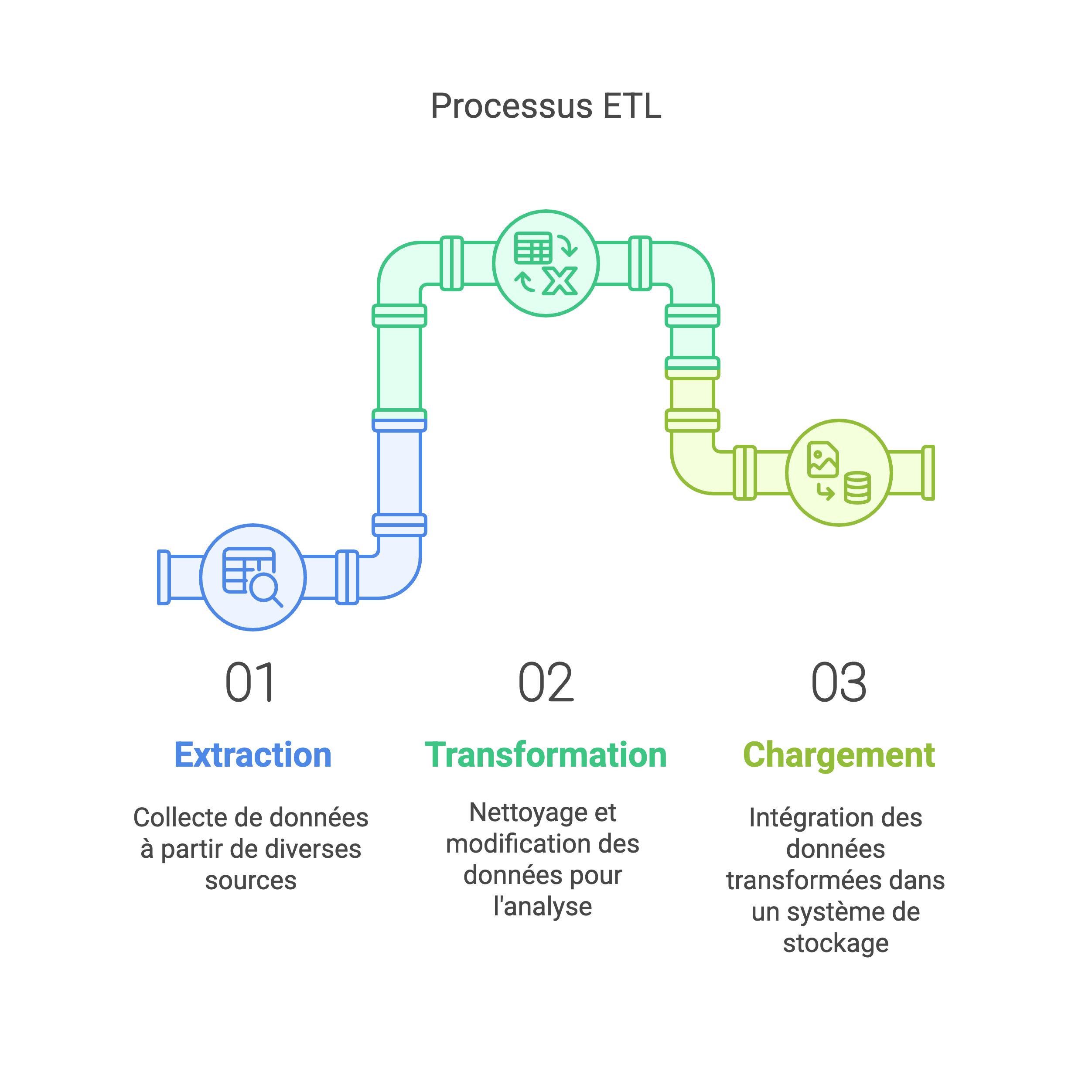
Qu'est-ce qu'un processus ETL ?
L'ETL est un processus t utilisé migrer les données d'une base de données transactionnelle vers une base de données analytique. Ce processus se décompose en trois étapes : Extract, Tranform et Load.
Extract (Extraction) : Les données sont récupérées depuis différentes sources, comme des bases de données, des fichiers CSV ou des API. L'objectif est de centraliser la donnée afin d'effectuer des analyses.
Transform (Transformation) : Les données extraites sont nettoyées, organisées et modifiées pour être prêtes à l'analyse. Cela peut inclure la suppression des doublons, la conversion de formats, ou la création de nouvelles informations à partir des données existantes.
Load (Chargement) : Les données transformées sont ensuite transférées dans une base de données analytique où elles peuvent être utilisées pour des analyses approfondies.
Le passage des bases transactionnelles à une architecture analytique est essentiel pour toute organisation qui veut tirer parti de ses données à des fins stratégiques. Voici comment cela se fait :
Fréquence des mises à jour : Les bases transactionnelles sont mises à jour en temps réel pour gérer les opérations quotidiennes. Par contre dans la plupart des cas, les bases analytiques n'ont pas besoin d'être constamment mises à jour. Généralement, des processus ETL sont exécutés à intervalles réguliers, comme toutes les heures, tous les jours ou de manière hebdomadaire, pour synchroniser les données.
Optimisation pour les requêtes : Les bases transactionnelles sont optimisées pour les transactions simples et rapides (comme des insertions, mises à jour, ou suppressions), tandis que les bases analytiques sont conçues pour des requêtes complexes impliquant des agrégations, des jointures multiples et des analyses de tendances.
Données historiques vs récentes : Les bases transactionnelles contiennent des données récentes tandis que les bases analytiques stockent souvent des historiques étendus, ce qui permet d'analyser les évolutions et les performances à long terme.
ETL permet de déplacer la donnée afin qu'elle soit analysée. Ce processus permet aux entreprises de passer d'une gestion opérationnelle à une stratégie basée sur l'analyse décisionnelle. Ensuite, il existe différents types de bases de données analytiques, comme le Data Warehouse, le Data Lake et le Lakehouse, chacun ayant un rôle spécifique dans le stockage et l'analyse des données.
Data Warehouse vs Data Lake vs Lakehouse
Dans l'écosystème moderne des données, tout professionnel travaillant avec l'information numérique doit avoir une compréhension approfondie des infrastructures fondamentales que sont les Data Warehouses, les Data Lakes et les Lakehouses. Ces architectures ne sont plus l'apanage des ingénieurs ou des architectes données, mais constituent un socle de connaissances essentiel pour l'ensemble des métiers de la data.
La maîtrise de ces systèmes permet de :
- Mieux collaborer avec les équipes techniques en parlant un langage commun
- Optimiser ses requêtes et analyses en fonction de l'architecture sous-jacente
- Anticiper les contraintes et opportunités liées à l'infrastructure en place
- Contribuer aux discussions sur l'évolution des systèmes d'information
- Proposer des solutions innovantes adaptées aux capacités techniques disponibles
Cette compréhension technique, même si elle n'implique pas nécessairement une expertise approfondie, devient un atout majeur dans un monde où la donnée est omniprésente. Elle permet aux professionnels de tous horizons - qu'ils soient marketeurs, chercheurs, décideurs ou opérationnels - de mieux exploiter les ressources à leur disposition et de participer activement à la transformation digitale de leur organisation.
Les frontières traditionnelles entre les différents métiers de la data s'estompent progressivement, créant un environnement où la polyvalence et la compréhension transverse des systèmes deviennent des compétences indispensables pour évoluer efficacement dans l'écosystème des données.
De plus, une bonne culture data enrichit son profil professionnel, ouvrant la voie à des opportunités d'évolution vers des postes nécessitant une vue d'ensemble. En effet, la maîtrise des concepts fondamentaux liés à la gestion des données peut positionner le Data Analyst comme un candidat idéal pour des rôles plus techniques comme celui d'analytical engineer ou des fonctions managériales comme lead data.
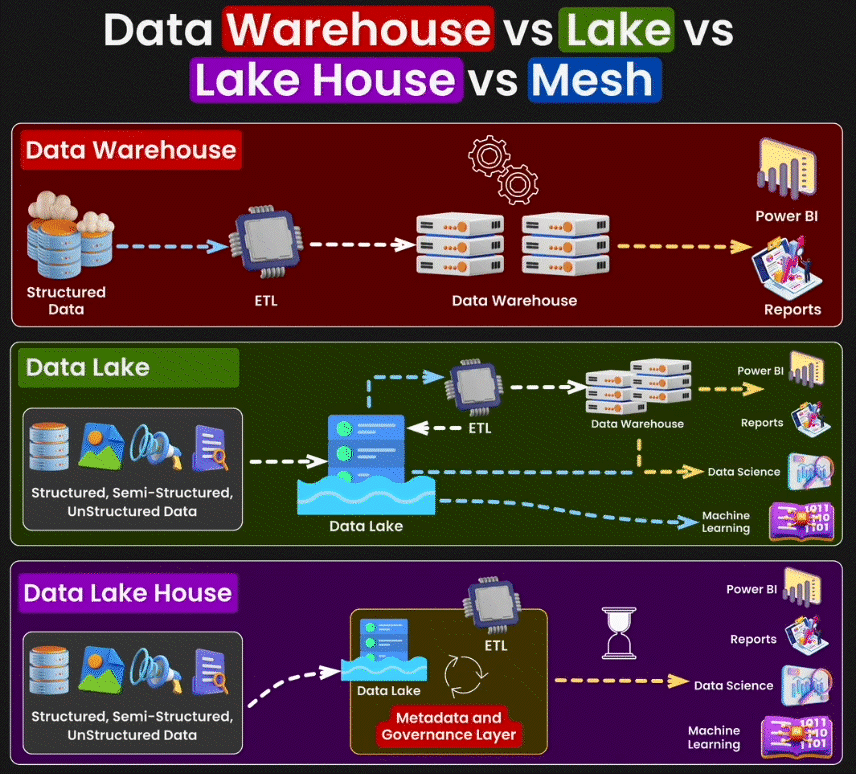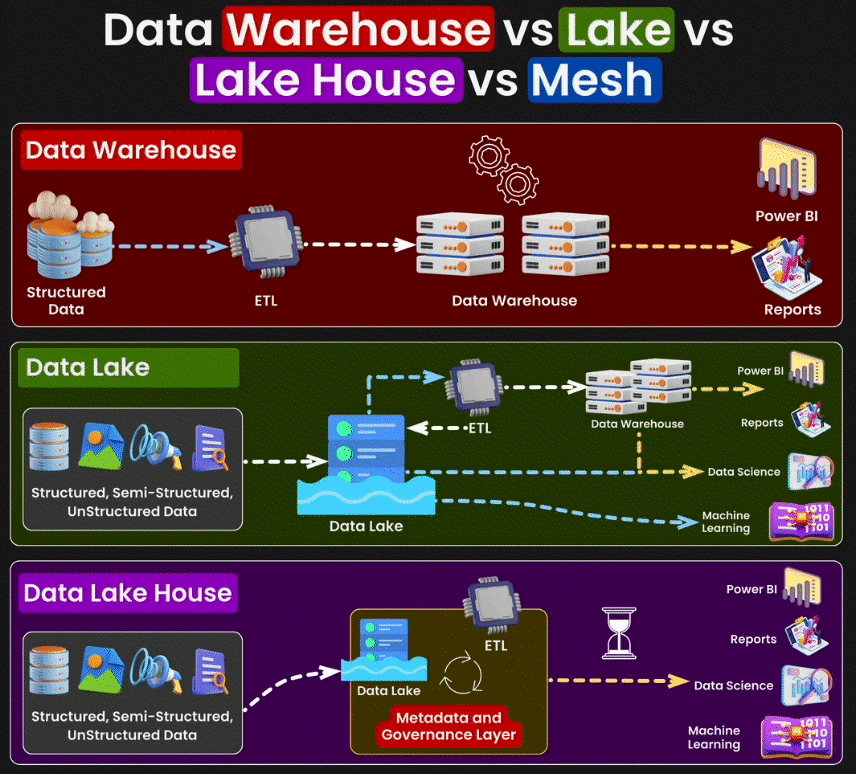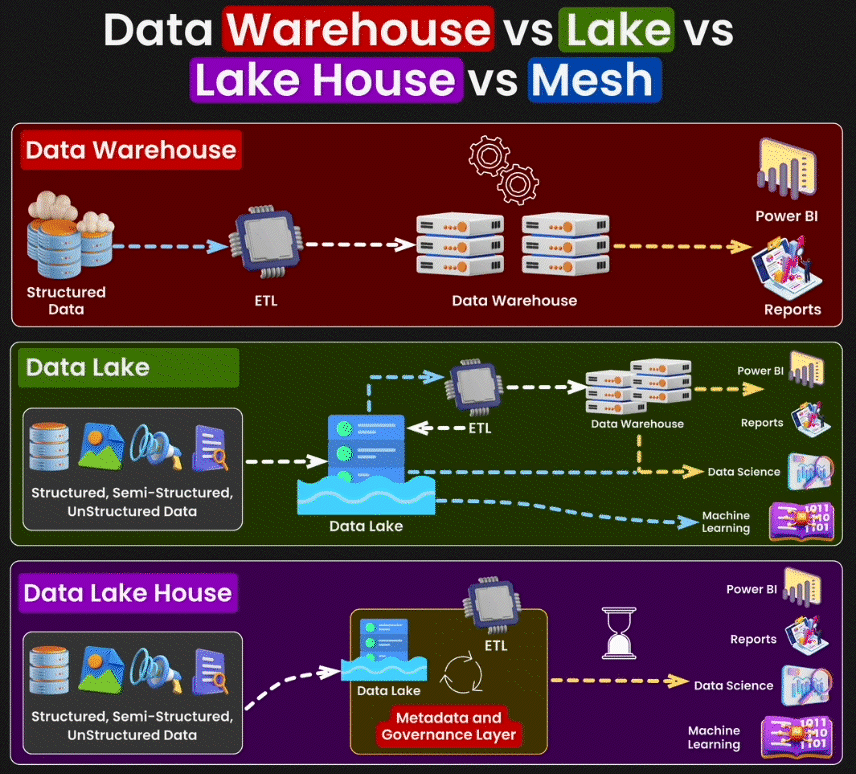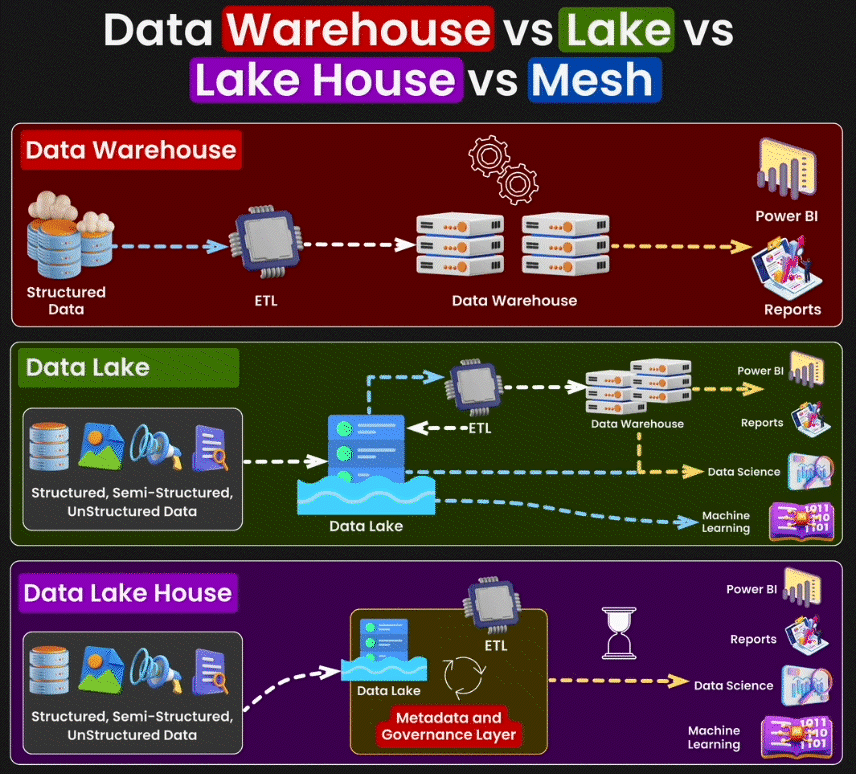
Data Warehouse
Un Data Warehouse est une base de données centralisée qui exige des données structurées, c'est-à-dire des données organisées selon un format précis. Prenons l'exemple d'un fichier CSV de ventes : chaque ligne représente une transaction, avec des colonnes aux types de données spécifiques - dates de vente en format date, montants en nombres, noms des clients en texte. Cette structure rigoureuse est essentielle pour le Data Warehouse.
Son objectif principal est de consolider ces données dans un format unifié et cohérent afin de faciliter l'analyse et la génération de rapports. Les données du Data Warehouse sont chargées à partir de systèmes opérationnels variés et d'autres sources externes, puis transformées pour assurer leur cohérence avant d’être stockées en vue d’une analyse. Ces entrepôts de données sont optimisés pour le traitement de requêtes et l’analyse de grandes quantités de données, offrant ainsi une vue globale des opérations et des performances de l’entreprise sur le long terme.
Exemples :
- Amazon Redshift : un entrepôt de données dans le cloud, partie d’AWS, optimisé pour l'analyse de données à grande échelle.
- Snowflake : un service d'entrepôt de données cloud qui sépare le stockage des données du calcul, offrant une scalabilité flexible et une gestion des données efficace.
- Google BigQuery : un entrepôt de données cloud entièrement géré qui permet l’analyse de grandes bases de données avec une infrastructure sans serveur.
Data Lake
Le Data Lake est une infrastructure de stockage conçue pour héberger des données massives sous leur format d'origine. Contrairement au Data Warehouse qui impose une structure prédéfinie lors de l'insertion des données, le Data Lake conserve les données telles quelles et n'applique de structure qu'au moment de leur utilisation. Il accepte à la fois les données structurées (csv), semi-structurées (json) et non structurées (pdf).
Cette architecture présente plusieurs avantages clés :
- Rapidité d'ingestion des données puisqu'aucune transformation n'est requise à l'entrée
- Conservation de la granularité maximale des données brutes
- Adaptabilité à de nouveaux cas d'usage non anticipés initialement
- Support natif pour l'exploration de données, l'analyse prédictive et le machine learning
Cette flexibilité en fait un composant essentiel des architectures data modernes, particulièrement adapté aux besoins d'innovation et d'expérimentation des organisations.
Exemples :
- Amazon S3 : un service de stockage d'objets offert par Amazon Web Services, souvent utilisé pour créer des Data Lakes en raison de sa fiabilité et de sa flexibilité.
- Azure Data Lake : une solution de Microsoft Azure qui permet de stocker et d'analyser de grandes quantités de données, optimisée pour le big data.
Lakehouse
Le concept de Lakehouse cherche à combiner les meilleures fonctionnalités du Data Lake et du Data Warehouse. Il s’agit d’une architecture de gestion des données qui offre la flexibilité et la capacité de stockage d’un Data Lake, tout en fournissant les capacités de gestion, de traitement et d’analyse des données structurées propres au data warehouse. Les Lakehouses permettent de réaliser des analyses avancées et des opérations de machine learning sur de grands ensembles de données, tout en assurant une gestion efficace des données et une intégrité transactionnelle.
Cette approche hybride vise à fournir une plateforme unique pour tous les types de données et d'analyses, réduisant ainsi la complexité et les coûts associés à la maintenance de systèmes séparés pour les données structurées et non structurées.
Exemples :
- Databricks : une plateforme unifiée basée sur Apache Spark qui offre des fonctionnalités de Lakehouse. Elle permet le traitement et l'analyse des données big data ainsi que le machine learning.
- Delta Lake : une couche de stockage open source qui apporte des fonctionnalités de gestion transactionnelle à Apache Spark et aux Data Lakes, transformant ces derniers en Lakehouses.
A retenir
Les bases de données transactionnelles et analytiques servent 2 objectifs différents mais complémentaires dans le paysage de la gestion des données : les premières facilitent les transactions quotidiennes et les opérations en temps réel, tandis que les secondes permettent une analyse stratégique et détaillée des données accumulées. Les processus ETL constituent le pont entre ces deux mondes, en extrayant les données des sources transactionnelles, en les transformant pour les rendre compatibles avec les besoins analytiques et en les chargeant dans les data lakes, data warehouses ou lakehouses. Selon les besoins spécifiques d'une organisation. Cette distinction est essentielle pour les organisations cherchant à optimiser à la fois leur efficacité opérationnelle et leur capacité d'analyse décisionnelle. Par ailleurs, il est important de noter que ces différentes architectures de données sont souvent soutenues par des systèmes de gestion de bases de données (SGBD), dont nous parlerons plus en détail dans le chapitre suivant.