
04. Metiers de la Data
Pour mener à bien l'exploitation des données, une équipe pluridisciplinaire est nécessaire. Chaque rôle et ses attributs sont représentés visuellement dans ce chapitre suivant. Cette approche vise à illustrer concrètement les responsabilités de chaque acteur au sein de l'écosystème des données. Les 12 critères ci-dessous servent de guide pour comprendre les compétences spécifiques requises pour chaque profession.
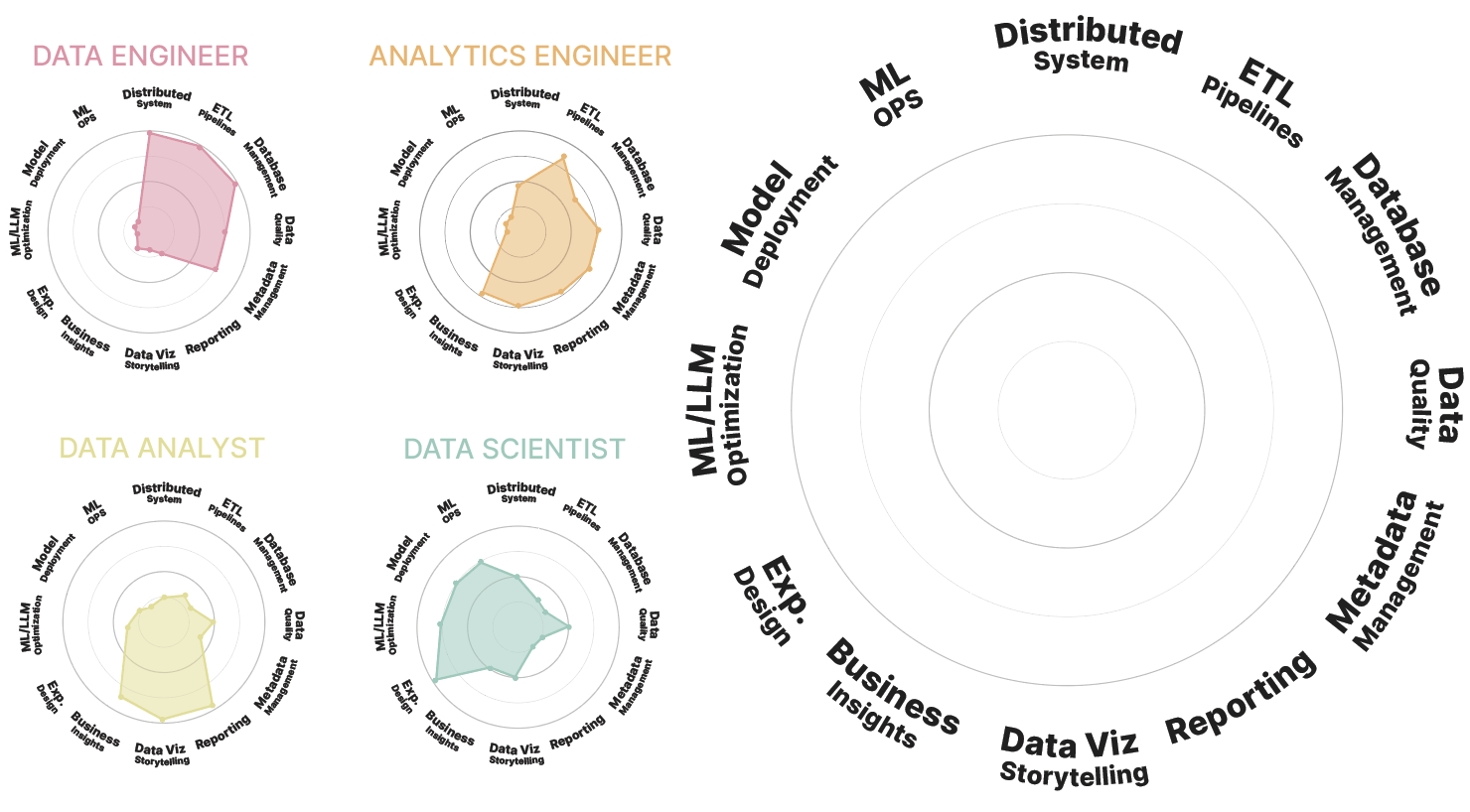
ML Ops : Machine Learning Operations (MLOps) unifie le développement et le déploiement des modèles ML en production via l'automatisation des pipelines, le versioning rigoureux et le monitoring continu, facilitant la collaboration entre équipes DevOps (test, déploiement, automatisation) et Data Science (création de modèles de machine learning).
Système distribué : Un système distribué connecte plusieurs machines indépendantes pour créer une infrastructure unifiée qui partage les ressources de calcul et de stockage, tout en assurant scalabilité et résilience aux pannes via des protocoles standardisés.
Pipelines ETL : ETL signifie Extract, Transform, Load. Un pipeline ETL est un ensemble de processus qui permettent d'extraire des données de sources multiples, de les transformer pour répondre à des besoins spécifiques et de les charger dans un système cible pour l'analyse.
Gestion de base de données : La gestion de base de données fait référence aux actions entreprises pour manipuler et contrôler les données tout au long de leur cycle de vie, incluant l'acquisition, le stockage, et la récupération.
Qualité des données : La qualité des données en informatique se réfère à la conformité des données aux usages prévus, représentant fidèlement la réalité à laquelle elles se réfèrent.
Gestion des métadonnées : La gestion des métadonnées permet à un utilisateur de rechercher et d'identifier des informations selon des attributs clés dans une interface utilisateur Web.
Reporting : Les dashboards sont l'outil privilégié du reporting moderne, offrant une visualisation en temps réel des données critiques via des graphiques, tableaux et indicateurs personnalisables selon les besoins des différents utilisateurs.
Data Viz Storytelling : Le data storytelling est l'art de raconter des histoires à partir des données. Il s'agit de donner vie aux données en personnalisant la restitution selon l'audience et en maîtrisant les techniques de narration et d'élaboration de visuels.
Business insights : Les business insights sont des informations exploitables qui découlent des statistiques effectuées. Elles aident à prendre des décisions stratégiques concernant les clients et les tendances du marché.
Exp. Design : L'Experience Design est une approche statistique qui structure la conception d'expériences et de tests (A/B testing, tests multivariés) pour mesurer rigoureusement l'impact des changements et guider les décisions business avec des données fiables.
ML / LLM Optimisation : L'optimisation en Machine Learning (ML) et en Large Language Models (LLM) implique l'ajustement des algorithmes et des modèles pour améliorer leur performance et leur efficacité.
Déploiement de modèle : Le déploiement de modèle en machine learning fait référence à l'intégration d'un modèle ML formé dans un environnement de production où il peut recevoir des données d'entrée et fournir des prédictions ou des résultats.
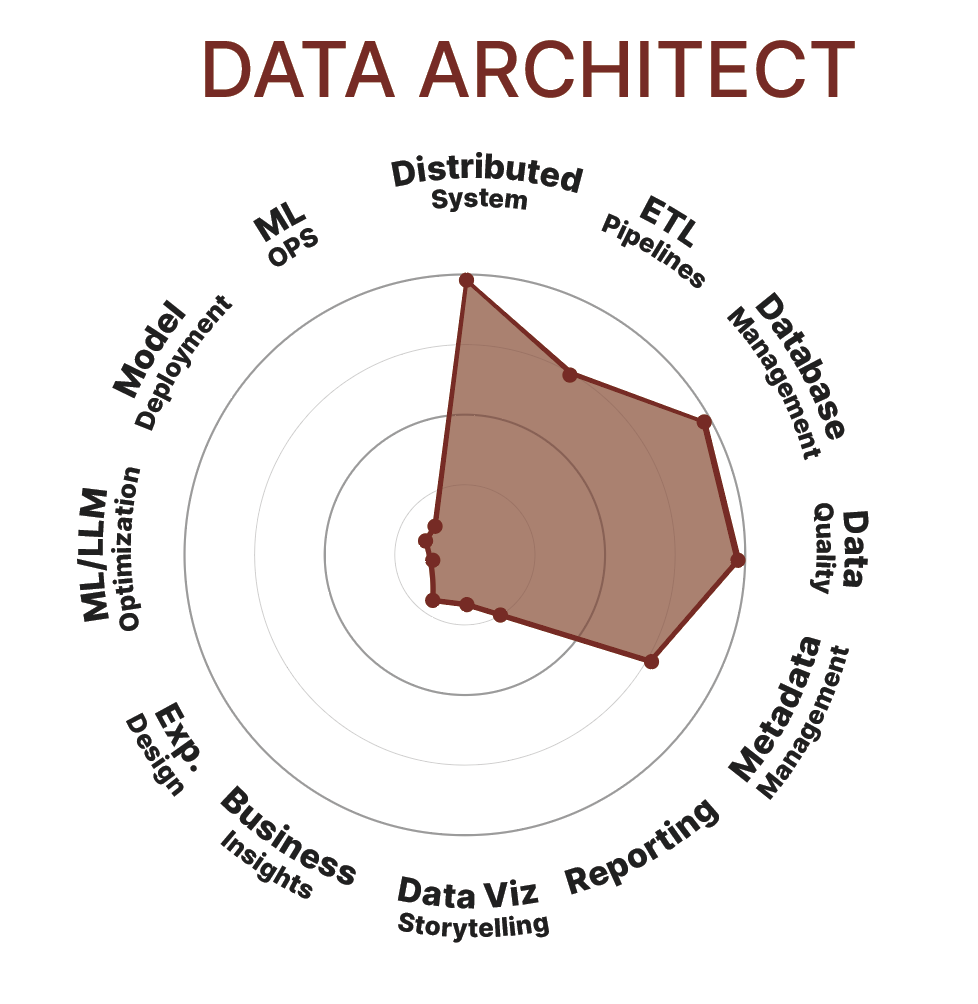
Data Architect
Rôle :
Le Data Architect (Architecte de Données) conçoit la structure globale des systèmes de gestion de données. Il définit les modèles de données, les schémas de bases de données et les stratégies de gestion des données. Il a une vision à long terme de l'évolution des besoins en données de l'entreprise et planifie en conséquence.
Responsabilités :
• Concevoir l'architecture des bases de données pour répondre aux besoins de l'organisation.
• Définir des standards pour la gestion des données.
• Collabore avec les Data Engineers pour mettre en œuvre l'infrastructure de stockage des données selon les conceptions architecturales.
• Collaborer avec les équipes de développement pour intégrer les bases de données dans les applications.
• Évaluer et recommander des technologies de bases de données.
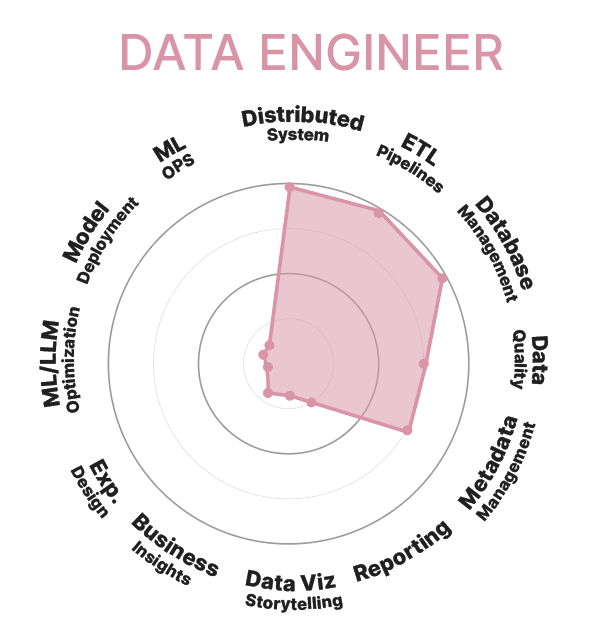
Data Engineer
Rôle :
Le Data Engineer (Ingénieur de Données) est responsable du transport de la donnée. Ils s'assurent que les données soient collectées, stockées et accessibles de manière efficace.
Responsabilités :
• Concevoir et mettre en œuvre des pipelines de données pour collecter, nettoyer et transformer les données.
• S'assurer de la qualité et de la cohérence des données.
• Collaborer avec les software engineers (ingénieur logiciel), les data scientists et les équipes métiers pour s'assurer qu'une donnée de qualité soit accessible.
Data Scientist

Rôle :
Le Data Scientist (Scientifique de Données) explore les données et construit des modèles qui visent à classifier, prédire ou générer des réponses. Ils utilisent des techniques statistiques et des algorithmes d'apprentissage automatique.
Responsabilités :
• Collecter et nettoyer des ensembles de données (70% du travail).
• Développer et appliquer des modèles prédictifs et de classification.
• Interpréter les résultats des analyses et les communiquer de manière compréhensible.
• Collaborer avec les équipes métiers pour créer des modèles qui correspondent aux besoins des équipes métiers (marketing, commerciaux, etc).
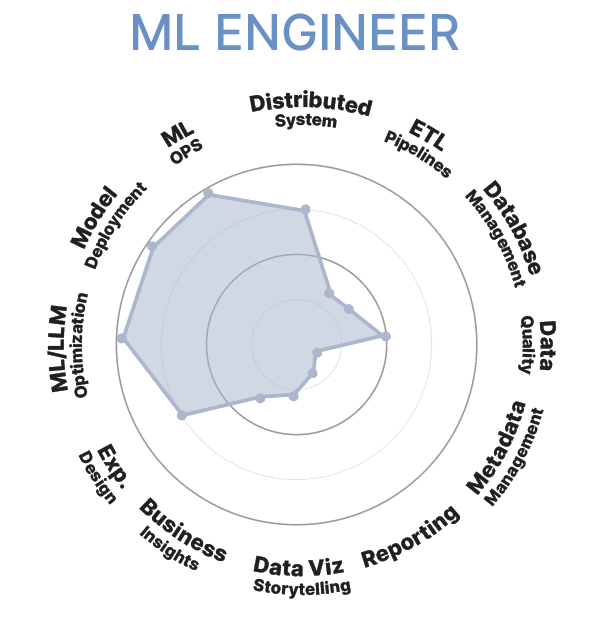
ML Engineer
Rôle :
Le Machine Learning Engineer (Ingénieur en Apprentissage Automatique) est responsables du déploiement et de l'optimisation des modèles d'apprentissage automatique. Son rôle consiste à construire des systèmes qui permettent de former, tester et déployer des modèles de machine learning en production.
Responsabilités :
• Implémenter des pipelines de machine learning qui automatisent le processus de collecte, de traitement et de modélisation des données.
• Collaborer avec les Data Scientists pour transformer les prototypes en modèles fonctionnels et opérationnels.
• Assurer le déploiement des modèles dans des environnements de production tout en garantissant leur performance et leur évolutivité.
• Surveiller les performances des modèles en production et apporter les ajustements nécessaires pour maintenir leur efficacité.
• Collaborer avec les software engineers (ingénieur logiciel) pour intégrer les modèles d'IA dans les applications.
Analytics Engineer
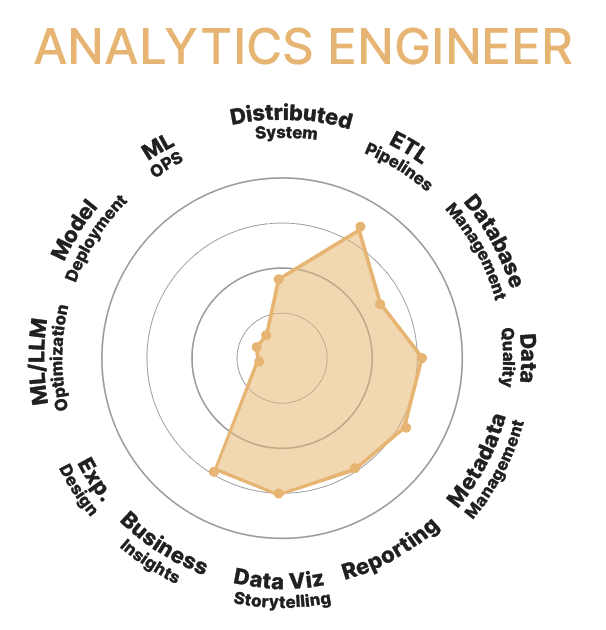
Rôle :
L'Analytics Engineers (Ingénieur en Analyse de Données) est chargés de transformer les données brutes en données prêtes pour répondre au besoins métiers. Il travaille principalement en SQL pour créer des modèles de données fiables et documentés, optimiser les requêtes, et maintenir la qualité des données.
Responsabilités :
• Nettoyer et transformer les données.
• Collaborer avec les Data Engineers pour garantir une intégration transparente des données.
• Mettre en œuvre des solutions pour la gestion de la qualité des données et la cohérence.
• Travailler en étroite collaboration avec les Data Scientists et les Analysts pour comprendre leurs besoins en données.
Data Steward
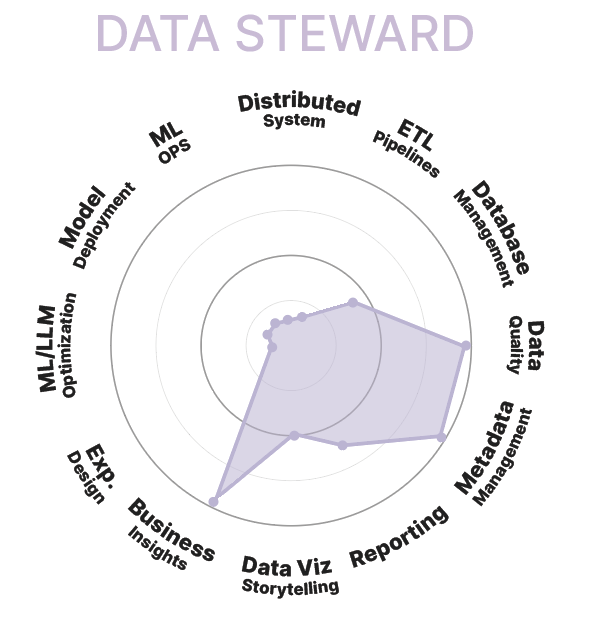
Rôle :
Le Data Steward est généralement un professionnel d'une équipe métier qui a une appétence pour la data. Il est spécialisé dans la gestion et la qualité des données. Son rôle principal est de garantir l'intégrité, la cohérence et la qualité des données au sein d'une organisation.
Responsabilités :
• Collaborer avec les data engineers pour assurer une collecte de données conforme et efficace.
• Surveiller et évaluer la qualité des données en remontant les incohérences et les lacunes.
• Veiller à la conformité, aux normes et réglementations en matière de gestion des données.
Data Analyst
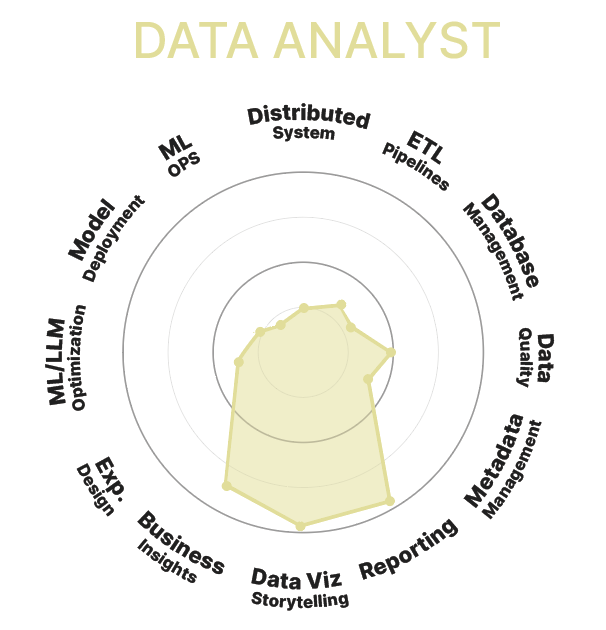
Rôle :
Le Data Analyst (Analyste de Données) examinent et interprètent les données pour aider les entreprises à prendre des décisions basées sur la donnée. Ils utilisent des outils d'analyse pour produire des rapports, des visualisations et des recommandations.
Responsabilités :
• Interroger et analyser des bases de données pour extraire des informations.
• Préparer des rapports et des visualisations pour présenter les résultats.
• Identifier les tendances, les modèles et les anomalies dans les données.
• Collaborer avec les équipes métier pour comprendre leurs besoins en données.
Exemple de projet data
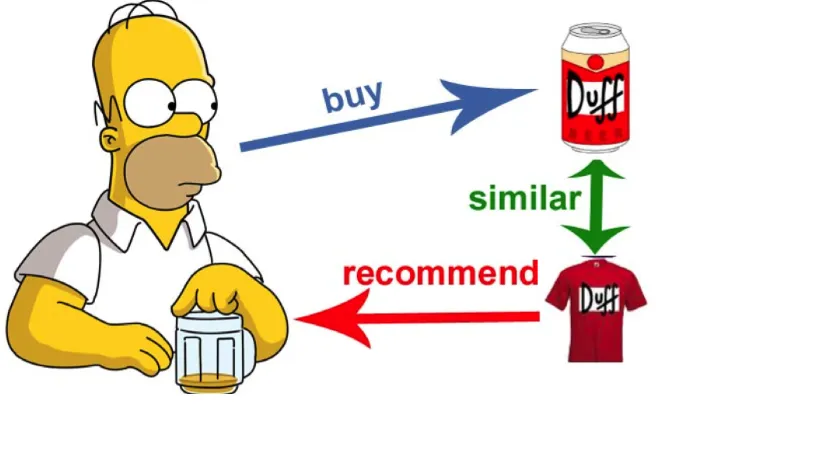
Prenons l'exemple d'un projet de recommandation de produits pour une plateforme de vente en ligne comme Amazon. Les Data Engineers créent des systèmes pour collecter des informations sur le comportement des utilisateurs, comme les pages qu'ils visitent et ce qu'ils achètent. Ensuite, les Analytics Engineers nettoient et organisent ces informations par thèmes pour répondre aux besoins de l'entreprise. Les Data Analysts utilisent ensuite ces informations pour informer les responsables, par exemple, sur les produits les plus vendus et expliquer les performances de ventes. Pendant ce temps, les Data Scientists créent des modèles pour recommander des produits adaptés à chaque utilisateur, ce qui augmente les chances de vente.
Le Machine Learning Engineer joue alors un rôle clé dans ce processus. Il est responsable de la mise en production des modèles développés par les Data Scientists. Cela implique d'optimiser les performances des algorithmes, de les intégrer dans les systèmes de l'entreprise, et de les déployer de manière scalable pour gérer le volume important de requêtes en temps réel. Il veille également à la surveillance continue des modèles en production, en ajustant les performances au besoin pour garantir des recommandations précises et pertinentes.
Une étude de McKinsey révèle que jusqu'à 35 % des ventes d'Amazon sont générées grâce aux systèmes de recommandations.
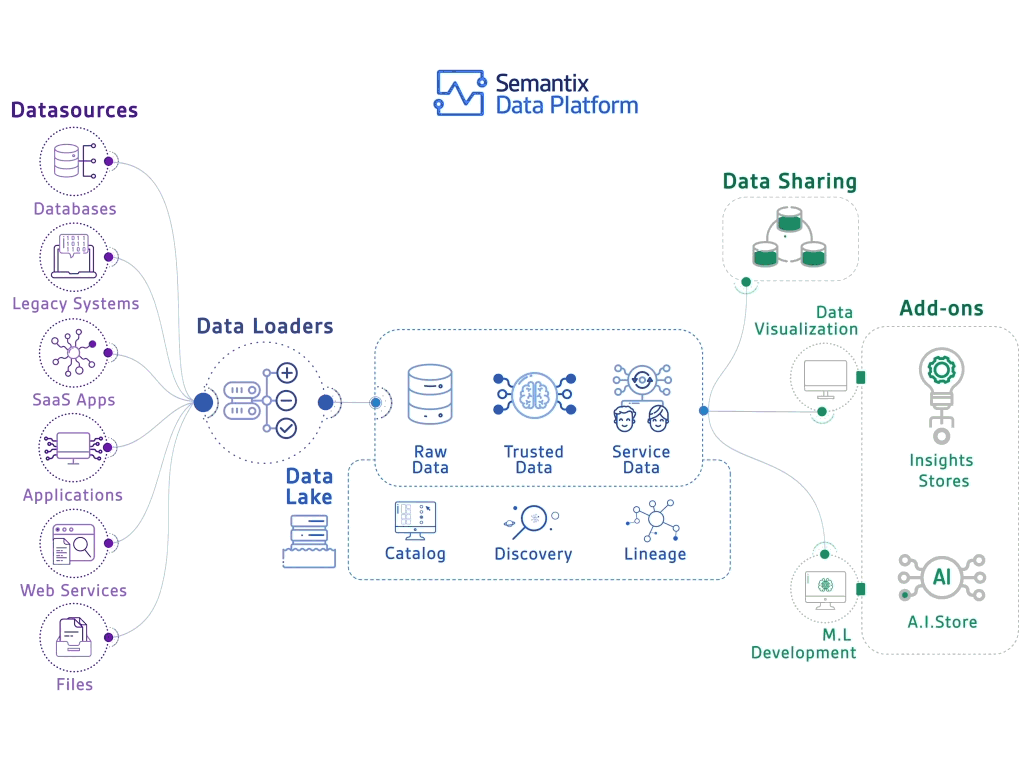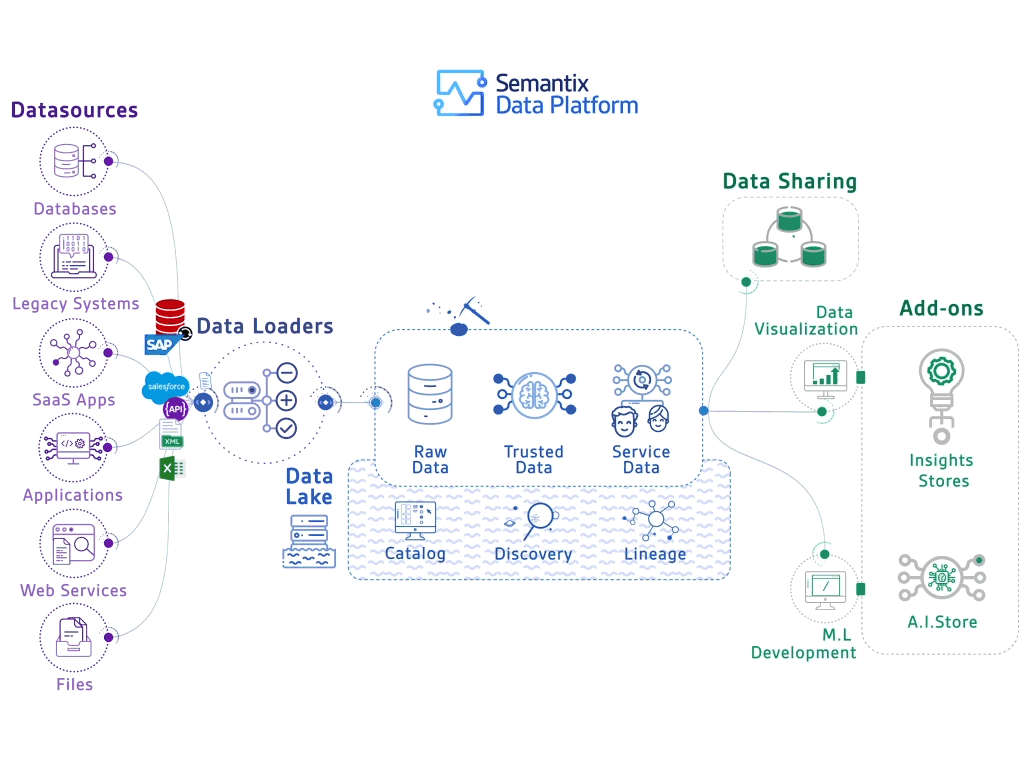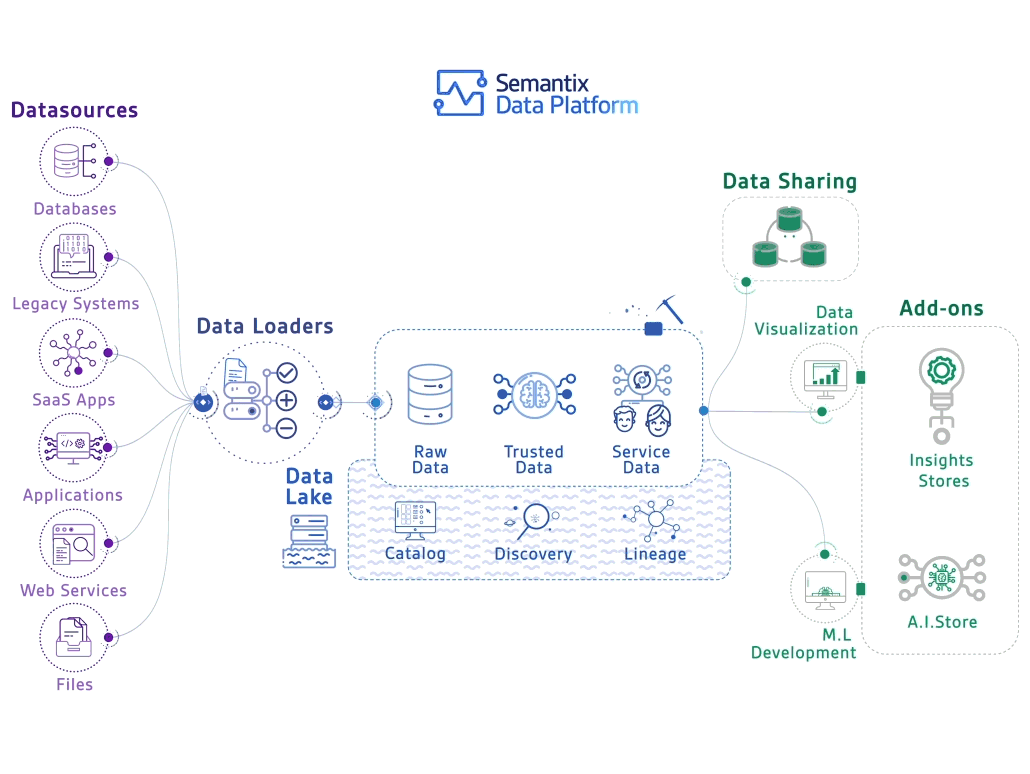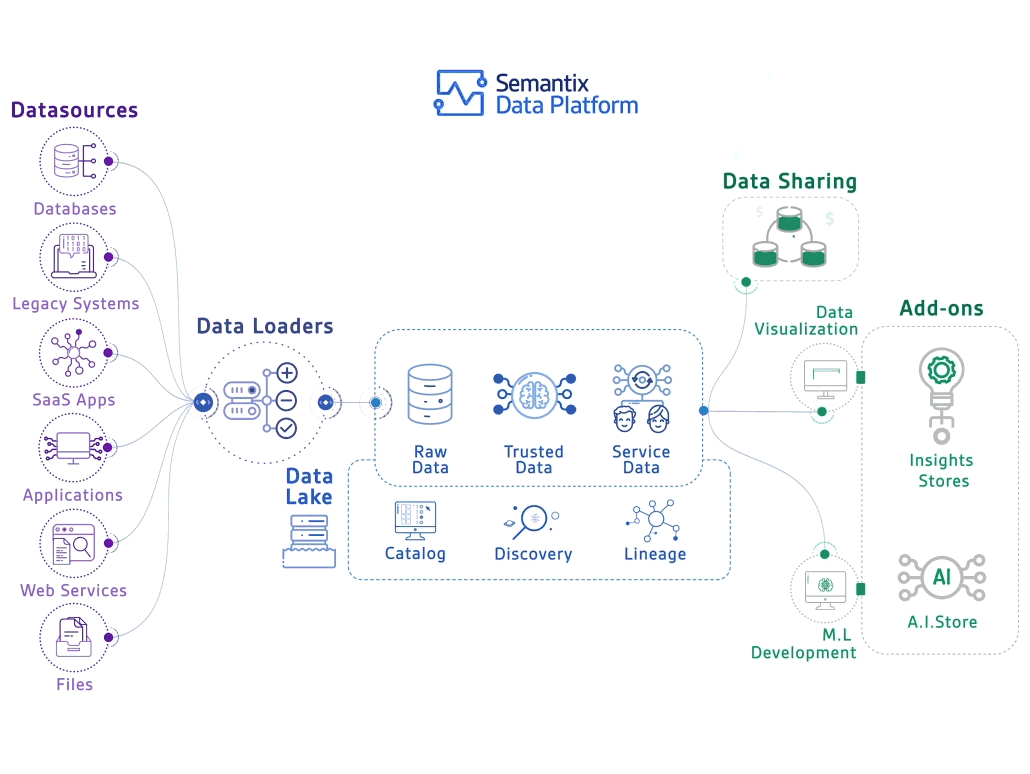
Par ailleurs, les Data Architects conçoivent l'infrastructure nécessaire pour supporter ces opérations à grande échelle, tandis que les Data Stewards s'assurent de la conformité des données avec les réglementations en vigueur.
L'écriture de Bonnes Requêtes
L'exploitation efficace des données est devenue un enjeu majeur pour toute personne travaillant avec des bases de données. Ce guide est conçu pour vous aider à maîtriser l'art d'écrire des requêtes pertinentes et performantes, une compétence essentielle dans le monde des données. Avant d'aborder les aspects techniques de l'écriture de requêtes, examinons les principaux défis à relever lors de l'analyse de données. Les analystes font face à 3 défis majeurs lors de l'exploitation des données :
Le volume : Le traitement de grands ensembles de données peut être complexe et exige des compétences pour gérer efficacement ces volumes massifs d'informations.
La qualité : Les données peuvent être incomplètes, inexactes ou non fiables, nécessitant des compétences pour nettoyer et préparer les données de manière adéquate.
Compréhension : Une compétence essentielle consiste à interpréter et à comprendre le sens des données afin qu'il n'y ait pas de mésinterprétation lors de l'analyse des données.
Au quotidien, les data analysts permettent de répondre à de nombreuses questions stratégiques pour comprendre et améliorer le fonctionnement d'une organisation. Une bonne maîtrise des requêtes est essentielle pour extraire les informations pertinentes des bases de données et ainsi éclairer la prise de décision. Voici des exemples de questions auxquelles ils répondent :
- Quels sont les produits les plus vendus au cours du dernier trimestre et quelle a été l'évolution des ventes ?
- Quel est le taux de conversion des visiteurs provenant de différentes sources marketing et quel canal génère le plus de revenus ?
- Comment évoluent les niveaux de satisfaction des clients au fil du temps et quelles sont les principales raisons citées dans les commentaires des enquêtes de satisfaction ?
- Quel est le rendement des investissements publicitaires sur les différentes plateformes et comment cela varie-t-il en fonction des segments de la clientèle ?
- Quels sont les facteurs qui contribuent le plus aux retours de produits et comment pouvons-nous réduire ces retours tout en maintenant la satisfaction client ?
A retenir
Pour mener à bien un projet data, il est essentiel de constituer une équipe pluridisciplinaire, composée de différents rôles clés tels que les Data Engineers, Data Scientists, Machine Learning Engineers, et Data Analysts. Chacun de ces professionnels joue un rôle spécifique et complémentaire. Par exemple, les Data Engineers créent les pipelines de données, les Data Scientists élaborent des modèles prédictifs, tandis que les Machine Learning Engineers veillent à leur déploiement et optimisation en production. En parallèle, les Data Architects conçoivent l'infrastructure nécessaire et les Data Stewards garantissent la qualité et la conformité des données. Cet ouvrage se concentre sur la pratique à travers des requêtes SQL dès le chapitre suivant.