
03. Système de Gestion De Base de Données
Les bases de données sont conçues pour stocker les informations. Cependant, pour les traiter, on a recourt à un Système de Gestion de Base de Données (SGBD). Cet outil fait office d'intermédiaire entre les bases de données et leurs utilisateurs, facilitant la gestion des données, que ce soit pour insérer, mettre à jour, supprimer ou interroger la donnée (en anglais on utilise l'acronyme CRUD - create, read, update, delete). Le SGBD est un logiciel qui fournit une suite d'outils destinés à la définition, la manipulation, la sécurisation et la gestion des données. En utilisant des langages tels que le SQL, les SGBD facilitent l'accès et la manipulation des données.
Architecture Client-Serveur
L'architecture client-serveur est au cœur de la plupart des SGBD, fournissant un cadre robuste pour le traitement et la gestion des données. Dans ce modèle, les clients (utilisateurs) envoient des requêtes au serveur de base de données qui les traite, puis envoie une réponse.
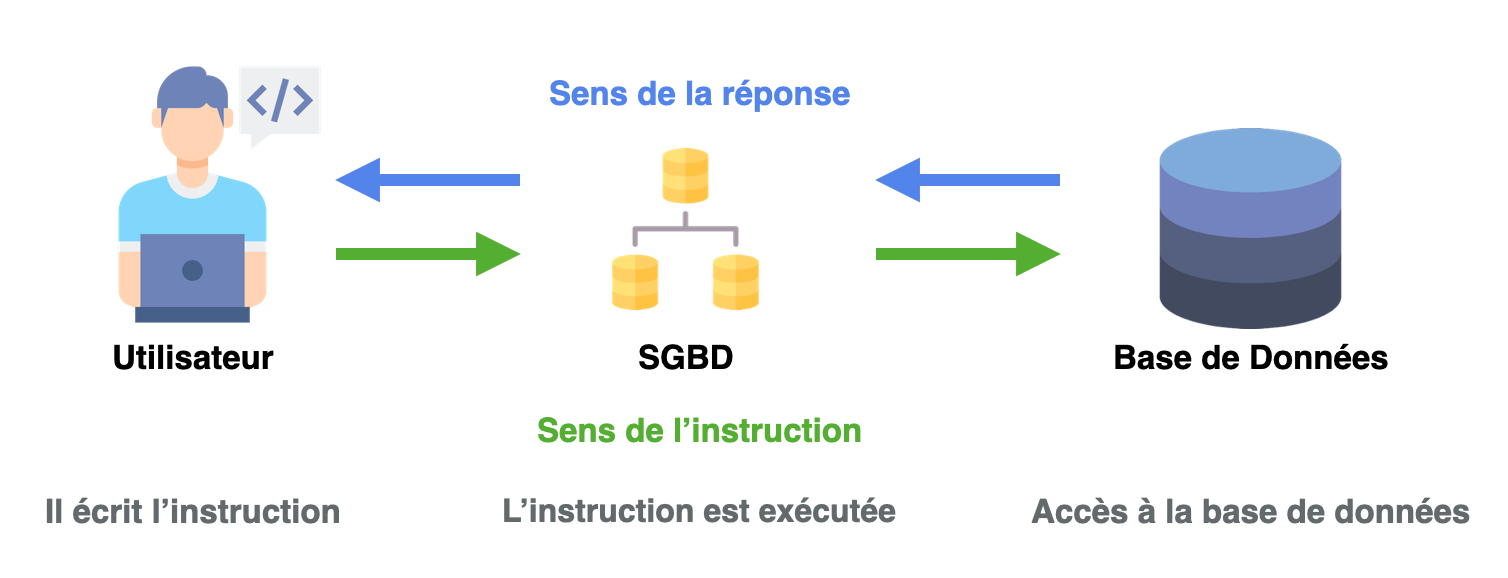
Le processus se passe de la manière suivante :
- Requête : Lorsque le client envoie une requête au serveur pour accéder à des données. Cette requête est généralement formulée dans un langage de requête structuré comme le SQL.
Réception de la requête : Le serveur reçoit la requête envoyée par le client. Le SGBD sur le serveur analyse la requête pour comprendre l'opération demandée (lecture, écriture, mise à jour, suppression).
Traitement de la requête : Le SGBD effectue plusieurs opérations internes telles que la vérification des autorisations de l'utilisateur pour s'assurer qu'il a le droit d'accéder ou de modifier les données demandées. Ensuite, il exécute la requête en accédant à la base de données stockée sur le serveur.
Optimisation : Avant d'exécuter la requête, le SGBD peut optimiser le plan d'exécution pour améliorer la performance et l'efficacité de l'accès aux données. Cette étape est cruciale pour des requêtes complexes sur de grands ensembles de données.
Envoi de la réponse : Après l'exécution de la requête, le serveur envoie les résultats au client. Cette réponse peut inclure les données demandées, une confirmation de l'exécution réussie d'une opération ou un message d'erreur en cas de problème.
Traitement de la réponse : Une fois que le serveur a traité la requête et exécuté les opérations demandées, le client reçoit les résultats. Ces résultats doivent être interprétés et affichés de manière appropriée, que ce soit au sein d'une application, d'un site web ou pour une analyse plus approfondie.
L'architecture client-serveur des Systèmes de Gestion de Bases de Données (SGBD) offre un cadre efficace pour la gestion des données, tirant parti de la séparation entre la demande d'accès (côté client) et l'exécution des requêtes (côté serveur). Cette organisation non seulement centralise la gestion des données mais améliore également la sécurité, facilite l'accès concurrentiel et optimise la répartition des charges de travail, ce qui entraîne une amélioration notable de la performance et de la fiabilité des systèmes de bases de données.
Fonctionnalités Principales
Les SGBD permettent aux organisations de toutes tailles de maximiser l'utilisation de leurs données, soutenant ainsi la prise de décision, l'optimisation des processus et l'innovation.
Les fonctionnalités principales des SGBD sont les suivantes:
• Définition de données : Ils permettent de définir la structure des données stockées, comme la création de tables (leur donner un nom), de champs (créer des colonnes) et de spécifications de type de données (la colonne est-elle de type numérique, texte, date ou autre).
• Manipulation de données : Offrent des fonctionnalités pour interroger, insérer, mettre à jour et supprimer des données (CRUD) à l'aide de langages de requête, tels que SQL.
• Sécurité des données : Incluent des mécanismes pour contrôler l'accès aux données, garantissant que seuls les utilisateurs autorisés peuvent accéder à l'information ou la modifier.
• Gestion des transactions : Assurent la gestion des transactions selon les propriétés ACID (Atomicité, Cohérence, Isolation, Durabilité) pour garantir la fiabilité et l'intégrité des données.
• Optimisation des requêtes : Utilisent des algorithmes avancés pour optimiser la façon dont les requêtes sont exécutées, améliorant ainsi la performance de la base de données.
• Sauvegarde et récupération des données : Offre des mécanismes pour sauvegarder les données et les récupérer en cas de défaillance du système ou de perte de données.
Ces avantages et fonctionnalités soulignent l'importance des SGBD dans la gestion moderne des données, offrant une plateforme robuste et flexible pour stocker, récupérer, et manipuler des informations de manière sécurisée et efficiente. Il existe plusieurs types de SGBD, chacun avec ses spécificités et ses avantages.
Types de SGBD
Les Systèmes de Gestion de Bases de Données (SGBD) constituent un élément fondamental de l'informatique moderne. Parmi la diversité des solutions existantes, les Systèmes de Gestion de Bases de Données Relationnelles (SGBDR) occupent une place prépondérante et c'est sur ces derniers que nous allons concentrer notre attention.
L'originalité et la puissance des SGBDR résident dans leur approche relationnelle. Imaginons un grand classeur où chaque feuille serait une table contenant des informations spécifiques. Ces tables ne vivent pas isolément : elles sont reliées entre elles par des liens logiques, créant ainsi un réseau cohérent d'informations. Cette architecture permet de représenter naturellement la complexité du monde réel tout en maintenant une organisation claire des données.
Exemple de table
| id | nom | salaire | service | rangSalaireService |
|---|---|---|---|---|
| 3 | Carol | 55000 | Ventes | 1 |
| 1 | Alice | 50000 | Ventes | 2 |
| 2 | Bob | 48000 | Ventes | 3 |
| 4 | David | 70000 | RH | 1 |
| 6 | Frank | 58000 | RH | 2 |
| 5 | Emma | 55000 | RH | 3 |
La table présentée ci-dessus, qui pourrait se nommer "Employes", illustre parfaitement cette organisation. Les données ont un format bien défini et la table se compose de colonnes (aussi appelées attributs) et de lignes (ou enregistrements).
D'autres Approches
Si d'autres approches existent, comme les bases NoSQL pour les données non structurées, les bases en mémoire pour les performances extrêmes ou encore les bases orientées objet. les SGBDR comme MySQL, PostgreSQL, Oracle ou encore SQL Server, excellent dans leur domaine de prédilection : la gestion rigoureuse de données structurées. Leur force réside notamment dans leur capacité à garantir l'intégrité des informations grâce à des mécanismes sophistiqués comme les transactions et les contraintes, faisant d'eux le choix privilégié pour les systèmes d'information critiques.
Evolution vers le Cloud
L'avènement des SGBDR (Systèmes de Gestion de Bases de Données Relationnelles) basés sur le cloud, tels qu'Amazon RDS, Google Cloud SQL, Azure SQL Database et SAP HANA Cloud, représente un tournant décisif dans le domaine de la gestion des données. Cette évolution marque une rupture avec l'approche traditionnelle "on-premise" (sur site), où les entreprises devaient héberger et maintenir leurs propres serveurs physiques dans leurs locaux. Dans ce modèle traditionnel, qui utilisait des solutions comme MySQL, PostgreSQL, Oracle Database et Microsoft SQL Server, les organisations étaient responsables de tous les aspects : l'achat du matériel, sa maintenance, la sécurité physique, la climatisation des salles serveurs et la gestion des sauvegardes.
Les nouvelles solutions cloud, en revanche, éliminent ce besoin de gérer une infrastructure physique, car tout est hébergé et maintenu par le fournisseur de services cloud. Cette approche offre une alternative plus flexible et souvent plus économique aux systèmes classiques, permettant aux entreprises de se concentrer sur leur cœur de métier plutôt que sur la gestion d'une infrastructure informatique complexe.
Là où l'on-premise nécessite une gestion complète de l'infrastructure par l'entreprise elle-même, le cloud propose un modèle où l'infrastructure est gérée par un tiers, offrant plus de flexibilité et généralement moins de contraintes techniques et financières.
Impact Économique
L'adoption des bases de données dans le cloud transforme profondément la structure des coûts informatiques des entreprises. En effet, cette transition réduit considérablement les dépenses en capital (CAPEX), traditionnellement consacrées à l'achat initial d'infrastructures comme les serveurs et le matériel de stockage. À la place, les organisations voient leurs dépenses opérationnelles (OPEX) augmenter, basculant vers un modèle de paiement flexible qui s'ajuste à leur consommation réelle de ressources. Ce changement de paradigme permet aux entreprises d'éviter les lourds investissements initiaux au profit d'une facturation régulière — mensuelle ou annuelle — qui reflète précisément leurs besoins effectifs. Si ce modèle semble attrayant initialement grâce à l'absence d'investissement massif de départ, l'accumulation des coûts opérationnels sur plusieurs années peut parfois dépasser le montant qu'aurait représenté l'investissement initial dans une infrastructure propre. Cette réalité est particulièrement vraie pour les entreprises ayant des charges de travail stables et prévisibles, où un investissement initial bien planifié pourrait s'avérer plus économique sur une période de 3 à 5 ans. Cette approche, bien qu'offrant une grande flexibilité, nécessite donc une analyse approfondie des besoins à long terme de l'entreprise et de ses patterns d'utilisation pour déterminer la solution la plus économiquement viable.
Avantages Additionnels
Scalabilité et Élasticité : Le cloud s'adapte automatiquement aux besoins des applications. Il augmente la puissance quand il y a beaucoup d'utilisateurs et la réduit quand l'activité est faible. Ainsi, seules les ressources nécessaires sont utilisées.
Maintenance Réduite : La responsabilité de la gestion des infrastructures, incluant la maintenance régulière, les mises à jour de sécurité et les sauvegardes, est déléguée au fournisseur de services cloud. Cela décharge les équipes informatiques des tâches de maintenance quotidienne, leur permettant de se consacrer aux tâches liées directement à la data.
Sécurité Renforcée : Les fournisseurs de cloud investissent massivement dans les technologies de sécurité de pointe et disposent d'équipes spécialisées pour sécuriser les infrastructures contre diverses menaces. Ce niveau d'expertise et de ressources dédiées à la sécurité est souvent difficile à égaler pour les entreprises gérant leurs propres systèmes on-premise, offrant ainsi une protection supérieure des données hébergées dans le cloud.
SGBDR Cloud
Amazon RDS est idéal pour les développeurs et les entreprises recherchant une intégration facile avec l'écosystème AWS, pour des applications web et mobiles nécessitant des bases de données relationnelles standards telles que MySQL, PostgreSQL, MariaDB, Oracle ou SQL Server. Sa capacité à se redimensionner automatiquement en fait un choix pertinent pour les startups en croissance rapide et les applications soumises à des variations saisonnières de la demande.
Google Cloud SQL s'adresse aux développeurs d'applications privilégiant une intégration étroite avec Google Cloud Platform. Parfait pour les projets utilisant Google App Engine ou Google Kubernetes Engine, il simplifie la gestion des bases de données MySQL, PostgreSQL ou SQL Server avec une maintenance et une analyse automatisées. Le rendant idéal pour les entreprises qui développent des applications nécessitant une grande échelle de données.
Azure SQL Database est optimisé pour les entreprises et les développeurs engagés dans l'écosystème Microsoft, cherchant à bénéficier d'une intégration profonde avec d'autres services Azure. Ce service est particulièrement adapté pour les solutions SaaS, les applications d'entreprise étendues et les migrations de bases de données SQL Server existantes vers le cloud, offrant des fonctionnalités avancées de sécurité et de performance.
SAP HANA Cloud convient aux entreprises qui utilisent déjà des solutions SAP et qui ont besoin d'une base de données en mémoire pour l'analyse en temps réel, le traitement des transactions et la consolidation des données. C'est une option stratégique pour les organisations cherchant à accélérer leurs processus décisionnels.
En résumé, l'évolution vers le cloud représente une opportunité pour les entreprises d'améliorer leur flexibilité et de se concentrer davantage sur la data et le développement de leurs applications sans avoir à gérer le materiel (hardware).
Limite du cloud américain
Les lois américaines jouent un rôle majeur dans l'accès aux données stockées dans le cloud. Tout commence en 2001 avec le USA PATRIOT Act, créé après le 11 septembre pour lutter contre le terrorisme. Cette loi permet aux autorités américaines d'accéder aux données des entreprises américaines, où qu'elles soient stockées dans le monde. En 2018, le CLOUD Act renforce et élargit ce pouvoir : les autorités peuvent désormais demander l'accès aux données pour toute enquête judiciaire, pas uniquement pour le terrorisme. Pour les entreprises utilisant des services cloud américains comme AWS ou Google Cloud, ces lois posent un véritable défi de confidentialité. En effet, même si leurs données sont stockées en Europe, elles peuvent être consultées par les autorités américaines. C'est pourquoi certaines entreprises se tournent vers des solutions alternatives, comme des fournisseurs cloud non-américains ou des systèmes de chiffrement spéciaux.
A retenir
Les Systèmes de Gestion de Bases de Données Relationnelles (SGBDR) permettent de stocker et gérer des données structurées en tables liées entre elles. On interagit avec ces bases principalement via le langage SQL pour créer, lire, modifier ou supprimer des données. Les SGBDR utilisent une architecture client-serveur qui sépare le stockage des données de leur utilisation. Aujourd'hui, ces systèmes sont disponibles dans le cloud avec des services comme Amazon RDS ou Google Cloud SQL. Cette évolution facilite leur utilisation : les ressources s'adaptent automatiquement aux besoins, les coûts sont optimisés et la maintenance est simplifiée.
Cela permet aux différents métiers de la data de gérer et analyser les données sans se soucier des contraintes d'infrastructure. Voyons cela dans le chapitre suivant.